한빌앤 MSA 세미나 2-7 : 볼트업 CTO 박순영 연사님의 "서비스 장애 잘 이해하고 대비하기" 오프라인 세미나를 듣고 정리한 글 입니다.
✔️ 세미나 Keyword : Reliability
- 서비스 장애를 주제로 어떤 원인에 의해서 발생하는지 이해하고 정의 내리고, 이를 잘 대응할 수 있도록 해보자
[목차]
- 어디까지 장애라고 볼 수 있을까?
- 장애는 어떻게 잘 대응할 수 있을까?
- 장애를 예방할 수 있을까?
- 부록: 장애 대응의 2가지 사례

(1) 장애의 정의 (어디까지 장애일까?)
🧐 간단한 오류도 장애에 포함해야 할까? → 장애를 나누는 기준
1. 서비스 장애의 기준
# 민감도와 심각도
민감도 (범위)
- 사용자 범위
- 장애 발생 시 어떤 사용자까지 피해를 보고 있는가 (개발자, 내부자, 전체 사용자 등)
- → 즉, 장애/오류를 경험하는 사용자 수를 의미합니다.
- 기능 범위
- 장애/오류로 인해 영향을 받는 서비스의 범위
- ex) 서비스는 돌아가지만 일부기능만 안된다. | 전체 기능이 안된다.
2. 서비스 장애의 범주
장애는 어느 수준까지 발생 할 수 있을까?
✔️ 서비스의 장애는 통제 가능 영역과 통제 불가능 영역으로 나눌 수 있습니다.

| 통제 가능한 장애 | 통제 불가능 | |
| 기술적 | 인적 | |
|
|
|
(2) 장애는 어떻게 잘 대응할 수 있을까?
1. 장애 대응의 원칙
- 장애는 “언제든 발생”할 수 있다.
- 최대한 “빠르게 감지”하고 “빠르게 복구”하며 “재발을 방지”한다.
✔️ 빠르게 감지
- 고객보다 먼저 감지하는 것
- 장애의 영향도 파악 후 공유가 필요하다. → 장애 징후 감지 후 심각도[장애 발생 시의 서비스 영향도] 파악 → 유관부서에게 전파까지
✔️ 빠르게 복구
- 임시 대처라도 장애 영향을 줄이자
(임시 대처로 인한 추가 장애 영역이 발생하지 않도록하자는 의미였던 것 같습니다.) - 잘못된 복구 대응이 되지 않도록 최소한의 장애 분석 필요
✔️ 재발 방지
- 상세 장애 원인 분석과 회고
- 장애로그 분석 등과 같은 심도있는 분석 필요
- ex) 트래픽 증가 → 서버 다운 → 로그 분석 → 장애 지점 파악 → 만약 redis 의 atomic 연산 부분의 비효울적인 사용이 원인이라면 → redis 오픈소스 장애 분석
- 재발방지를 위해 이런 식의 깊이있는 분석이 필요
- 가능한 완전한 솔루션 적용 (이상적인 이야기😭)
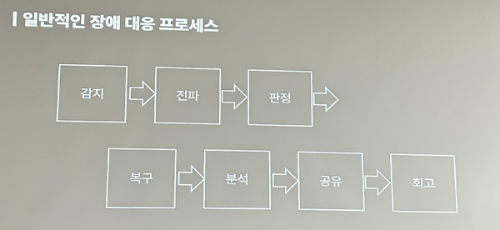
2. 일반적인 장애 대응 프로세스
감지 → 전파 → 판정 → 복구 → 분석 → 공유 → 회고
3. 시스템의 가시성
- 평소 모니터링 시스템을 구축하여 원인 분석의 단서를 확보해 두는 것이 중요하다.
- 빠른 장애대응을 위한 시스템 가시성을 확보하자

📌 도식화
- 시스템 가시성 확보의 순차적인 프로세스
1. 시스템
2. 모니터링 [APM, ELK, Prometheus 등]
- 시스템 지표/로그
- 인프라 장비 지표
- 미들웨어 자체 로그
- CPU/Memory 등의 사용량
- 네트워크 지표
-어플리케이션 지표/로그
- 어플리케이션. 로그
- JVM, 스레드 등의 지표
- 처리 시간 등의 지표
- 이슈 트래킹 : 비슷한 에러에 대한 그룹화..?
3. 전파 시스템
- 에러 감지 시, 해당 담당개발자에게 전파가 되어야 함4. 장애 대응할 지점 파악하기 : 약한 고리부터 탐색하기
✔️ 최근 주요한 변화 찾기 → 롤백 증설?
- 코드 변화, 배포
- 트래픽의 변화
- 구성 환경의 변화
- 데이터(캐시 포함)의 변화
✔️ 연관 취약점 탐색 → 복구 조치/ 회고
- 경험에서 유력한 후보 고려 : 먼저 일반적으로 에러가 발생할 수 있는 상황 탐색 [경험 및 다양한 사례가 필요]
- 소거법으로 하나씩 제거
5. 장애 회고와 피드백
📌 장애 대응을 했다면 회고를 해야한다.
📌 조치는 빠르게 해도, 분석은 low 레벨까지 해야한다.
✔️ 장애 조치는 빠르게 대응하더라도 정확한 원인 파악까지는 시간이 걸릴 수 있다.
- → 임시 조치로 인한 복구시에는 완전 조치로까지 이루어져야 한다.
- → 당시 모니터링 시스템에서 수집된 정보들로 최대한 하위 레벨까지 분석해야한다.
✔️ 장애에 대한 후속 조치
- 원인에 따라 고객이나 시스템에 대한 후속 조치가 필요하다. (CS or Data)
- 정확한 원인 파악 후에는 시스템 개선을 진행한다.
✔️ 회고와 공유
- 장애 재발 대책과 조직 내 공유를 통한 학습과 고객 공지가 필수로 이루어져야 한다.
- 당시 원인에 의한 지표, 로그 패턴들을 고려하여 장애 대비 및 성장을 위한 회고를 하는 것이 좋다
(3) 장애를 예방할 수 있을까?
성능 지표를 통한 모니터링환경을 구축하여 가시성 높은 시스템을 만들자
1. 인프라 설치 및 관리하던 시스템 관리자로부터 출발하여 클라우드의 출현으로 서비스 안정성을 책임지는 엔지니어링의 발달
2. 컴퓨팅 파워가 증가, 인프라와 클라우드 시스템의 발달, 다양한 에러상황의 생성 → SRE 관련 측면이 중요해짐
↓
SRE(Site Reliability Engineering, 사이트 신뢰성 엔지니어링)
- IT 운영에 대한 소프트웨어 엔지니어링 접근 방식입니다.
- SRE 팀은 소프트웨어를 툴로 활용하여 시스템을 관리하고, 문제를 해결하고, 운영 태스크를 자동화합니다.
장애 발생시 즉각적인 처리를 위한 태도
- 시스템의 상태와 가용성 확인
- 문제에 대한 긴급 대응
- 변화의 추적과 관리
- 서비스 트래픽의 수요 예측
1. 주요 시스템 지표의 정의
- 가용성에 대한 지표: Usage (사용량)
- Connections
- Usage, Utilization (Server, Pod, Pool, CPU, Memory)
- 응답 성능에 대한 지표 : Latency (지연성) - 응답 성능
- Write/Read IO
- Network Latency (각 구간별)
- Application Latency (각 시스템 별)
- Query
- 오류에 대한 지표
- Error Rate (5xx, DeadLock, Exception Rate 등)
2. 가시성 있는 모니터링 시스템
오토스케일링 등을 사용하자
장애 전에 특정 지표를 활용하여 파악해 미리 예방할 수 있도록 하는게 중요
✔️ 가시성 있는 모니터링 시스템을 구축해야하는 이유
- 감지와 대비를 위해서도 중요
- 특정 패턴 발생 또는 임계치 근접 시 사전 대응올 장애에 사전 조치가 가능하다.
- 장애 회고에 의한 학습으로 장애 사전 예방
- 적절한 임계치 설정과 알람 설정으로 사전 대응으로 장애 예방
3. 빠른 감지와 전파 시스템
위에서도 말했지만, 가시성있는 모니터링 시스템으로 장애 징조를 파악했다면 → 담당자에게 전파할 수 있는 시스템까지 구축해보자~~
4. 신뢰성 있는 테스트와 품질관리
1) 조직 내 테스트와 QA에 대한 적절한 체계가 수립되고 운영되어야 함
- 속도와 품질의 균형
- 배포 주기와 버전 관리
- 배포 기능의 명확한 추적 및 릴리즈 노트 작성 (장애 파악에 용이)
→ 단, 회사 사정과 규모에 따라서 어디까지 적용해야할지가 다르다.
→ 하지만 ! 릴리즈 노트만은 작성하자~~
2) 적절한 테스트 코드, 코드 품질을 유지하는 개발 문화
- 변화 후 사이드 이펙트 방지
- 개발 의도의 공유
- 지나친 의존성 지양
- 코드 리뷰를 통한 원칙 유지
5. Tolerance 가 높은 시스템 설계
✔️ 각 시스템 별 실패에 대한 고려로 장애 발생 시에도 서비스의 가용성 최대화 하자
- 데이터베이스의 실패
- → "데이터 베이스 이중화"
- 서버간 통신의 실패
- → Fallback 메소드 구현 [하나의 서버에 너무 의존하지 않도록 하는 것 (이것도 서킷 브레이크(임시 응답, 트래픽 파킹)로 대응 가능)]
- 급격한 트래픽의 대응 실패
- → 파킹 서버, 서킷 브레이커
- 배포 실패
- → 빠른 롤백, 블루그린 및 카나리 배포
- 인프라 실패
- → 각 인프라의 이중화, 임시 백업 시스템
(04) 부록: 장애 대응의 2가지 사례
## 1. 티켓팅 시스템의 서비스 전면 장애 사례
[문제 상황]
- 유명하지 않았던 서비스의 티켓팅 이벤트를 오픈
- 트래픽의 증가
- 레이턴시의 증가, 커넥션이 증가하지 않음
- 데이터베이스 CPU 점유율 상승
[장애 원인 파악]
- 티켓팅 해당 로직 장애 테스트 했음 → 하지만 예상하지 못했던 회원가입이 몰림(유명하지 않았던 서비스였기 때문에)
- 외부 메일 서버의 장애 였음
- 회원 가입 시의 메일 처리 비동기 스레드 수 증가 → 타임아웃이 너무 길고, 감지가 늦음
- 스레드 한계치 사용으로 서버 자원 부족
- 요청 응답에 성능 저하 및 전면 장애
- 응모 등의 화면에서 데이터베이스 쓰기 증가
- 응모 시의 과도한 트래픽이 Write DB로 바로 접근
- Slave / Read DB만으로 대응 불가
- 과도한 락 사용으로 점유 증가
- 응모 시의 과도한 트래픽이 Write DB로 바로 접근
- 결국 서버를 올려도, 커넥션이 없어서 대기하다가 스레드 증가로 다시 다운 (서버 자원의 부족) → 전면 장애
[임시 조치]
- 회원가입시 메일 인증을 잠시 스킵함
- 이후 서비스가 안정화 되었을 때 복구 메일로 다시 인증 절차 진행
[내가 느낀점] : 듣기만 해도 아찔하다,,
- 스트레스 테스트 중요하다.
- 외부 써드 파트 API 부분에서 장애가 날 수 있다는 것을 열어 두자
- 임시 조치라도, 그로인해 장애 다시 발생하지 않게 시간이 조금 더 걸리더라도 침착하게 대응하고 이후 완전 조치로 마무리하자
## 2. 클라이언트 앱의 HTTP 요청의 일부 사용자 요청 실패 사례
[문제 상황]
- 모바일 앱에서 서버로 데이터 요청 시 일부 사용자들만 안됨
- 클라이언트의 요청 건수와 Web(Nginx, Ingress) 서버로 유입되는 실 커넥션 수가 다름
- 일부 클라이언트에서는 요청 실패 오류의 증가

[원인 파악]
- 일부 모바일 OS에서 쿠버네티스 버전 업데이트 작업에 따른 TLS 스펙 미지원
- 인그레스에서 지원 TLS의 버전 변경이 가해짐
- 과거 OS에서 TLS 암호화 미지원으로 오류 발생

정리 끝..!
(추가) 가볍게 정리한 Q&A 내용
1. 장애가 나면 당황하지 말자~
- 데이터 복구전에 복구한 데이터 때문에 추가적인 장애는 없는지 한번 더 확인하자
2. B2c 중요 지표
- 일반적으로 CPU, Memory 20~30 % | 50% 넘어가면 증설 필요
- Db, Persitantcy 레이어 단의 지표
⭐️ 3. 로그 잘남기는 방법 ⭐️
- API 요청 로그 당연 (요청 바디, 응답 로그) → 단, 로그가 너무 커지기에 response 는 주로 유효기간을 두어 따로 빼서 남기는 것을 추천
- 데이터 생성에 관련된 로그는 미들웨어 로그로 대응 가능(DB)
장애 회고는 어떻게
- 타임라인 : 원인
- 대응, 등
참고
- 한빛앤 MSA 세미나 (이전 세미나 링크) : https://www.hanbitn.com/seminarwelcome/
- 박순영 연사님 링크드인 : syparkme
'🔥 공대생은 성장 중 > 세미나' 카테고리의 다른 글
| 2024 항해 데브랩 후기 (0) | 2024.09.02 |
|---|---|
| [한빛앤 MSA 세미나] 모니터링 | 강동호 (0) | 2024.08.20 |
| ⚙️ Block, Non-Block, sync(동기), Async(비동기) 의 간단한 개념 (0) | 2022.10.31 |
| [Restful api 란] - 진짜 Rest API 란 무엇이고 어떻게 써야하는 걸까? (2) | 2022.07.21 |