해당 포스팅은 인프런 "리눅스 성능 분석 시작하기" 를 수강하고 정리한 글입니다 :)
- 리눅스 기반 os 에서 돌아가는 서버 시스템의 성능 측정 및 장애 대응에 대한 학습 내용 정리 글 입니다.

[목차]
- nginx miss configuration
- 간헐적인 네트워크 응답 지연
- 간헐적인 커넥션 동료 에러
- 간헐적인 타임아웃
- EC2 CPU MHz이상 동작 에러
1. nginx miss configuration
nginx workers 설정 미숙으로 인한 장애
✔️ 장애 현상
- 트래픽 증가와 함께 서버의 응답 지연 발생 → 응답 지연은 컴퓨팅 리소스 부족이 원인
✔️ 트러블 슈팅 과정
1) 메트릭 수집
- 보통 응답지연은 컴퓨팅 리소스 자원의 부족을 원으로 보기 때문에 아래 2가지 관점에서의 메트릭 수집을 진행
- cpu usage : cpu 사용량이 많아서 응답을 못하는 것인가?
- MEM Usage : 메모리 사용량이 높아서 OOM이 발생 했는가?
👏🏻 top 으로 cpu와 memory에 대한 메트릭을 수집하고 파악가능
- 단, 멀티 코어일 경우 반드시 모든 코어의 CPU 사용률을 확인해야 함
2) 실제 장애 현상
예시) top 으로 확인해 본 결과 → 8개의 CPU 중 한 개의 CPU 100%를 사용중인 장애현상이 발생
- 의도적으로 싱글스레드로 동작하게 한게 아니라면 이상 현상임
3) 문제 원인 해결
결론적으로, Nignx의 worker_processes 가 잘못 설정되어있었다고 합니다.
- nginx worker_processes 란, 설정 중 워커 프로세스의 개수를 설정하는 항목
- 워커 프로세스란, 사용자의 요청 처리하는 프로세스를 말합니다.

→ nginx 의 기본 설정 worker_process 의 default 값은 1로 설정 되어있습니다.
즉 실제 동작하는 프로세스의 개수를 1로 제한한다는 의미이고, 이로인해 멀티코어임에도 불과하고, 1개의 cpu 만이 돌아가는 싱글 코어상태로 동작하는 문제였다고 합니다.
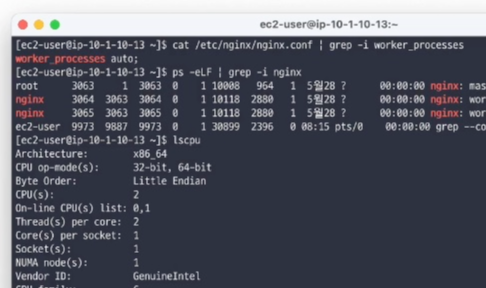
해당 사진 처럼 worker_process를 auto (cpu 개수에 맞게 만들겠다는 옵션) 로 설정한다면,
예시같은 문제 상황일 경우 워커프로세스 1 → auto로 수정 시 서버가 8배 늘어난 것과 같은 성능 업이 일어납니다.
✔️ 결론
- CPU 사용량 모니터링을 잘하자 (멀티 코어일 떄도)
2. 간헐적인 네트워크 응답 지연
Read Timeout으로 인한 장애
✔️ 장애 현상
- 간헐적으로 API 호출 시 타임아웃이 발생
- 응답을 안받았는데 먼저 커넥션을 종료시켜 버림 (타임아웃)
- 이 후, 커넥션 종료 후 응답이 오는 상황

✔️ 메트릭 수집
- netstat 을 통해 네트워크 연결은 잘 되어 있는지 확인 →establish 상태인지, close_wait 상태인지는 아닌지
- tcpdump를 통해 피킷들의 흐름을 수집 후 분석해야함
✔️ tcpdump 낚시
- 간헐적으로 발생하기 때문에, 긴 호흡으로 패킷을 수집해야 함
- tcpdump 참고 링크
1) 패킷 수집 순서
- tcpdump -vvv -nn -A -G 3600 -w /var/log/tcpdump/$(hostname)_%Y%m%d-%H%M%S.pcap : 1시간에 1번씩 해당 위치에 패킷 파일을 재생성
- 타임아웃이 발생한 순간 → tcpdump 수집을 멈추고 해당 순간이 pcap 파일을 분석
✔️ 클라이언트의 타이아웃 설정 살펴보기
🫥 Timeout 이란
- “현재 상태가 정상이라고 판단할 때까지 얼마나 기다릴 것인가” 에 대한 설정 → 이 시간이 지나면 에러라고 판단
🫥 Timeout의 종류
- Connection Timeout
- 종단 간 연결을 처음 맺을 때의 time out
- 3way tcp handshake
- Read Timeout
- 종단 간 연결을 맺은 후 데이터를 주고 받을 때
- 이미 커넥션을 맺은 상태에서, 데이터를 주고 받을 때 일어나는 time out
- Round Trip Time (RTT)
- 패킷이 종단 강ㄴ을 이동할 때 걸리는 시간, 즉 물리적 거리에 따른 시간
- 서울 ↔ 부산 왕복보다 // 서울 ↔ 미국을 왕복하는데 훨씬 많은 시간이 걸린다.
- 이 시간을 Round Trip Time 이라 함
🫥 Round Trip Time (RTT)
- 타임아웃 시 RTT 를 고려해야하는데, 아래 사진처럼 RTT의 요청시간이 존재한다고할 때
- Read timeout 은 RTT + 평균 요청 처리시간이 되어야합니다.

🫥 Timeout 설정시 고려해야하는 상황 2가지
1. RTT를 모를 때
-
- 패킷이 한 번도 흘러본 적이 없으니, RTT 시간이 얼마나 걸릴지 알 수 없습니다.
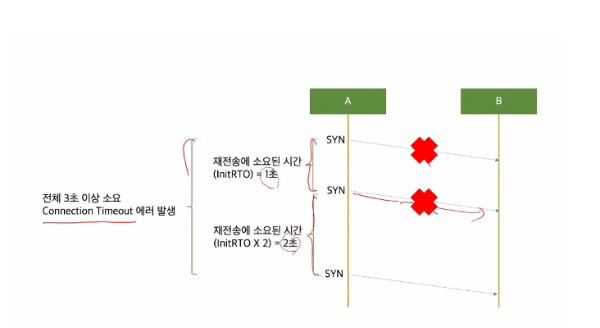
- initRTO : RTT를 모를 때 사용하는 커널의 패킷 초기 타임아웃 값 (리눅스는 1초로 하드코딩 되어있습니다.)종단 간 커넥션을 처음 맺을 때
👏🏻 Connection Timeout 설정
- 3-Way Handshake 과정 중 최소한 한 번의 패킷 유실 정도는 방어할 수 있어야 합니다.
- 그렇기 때문에, 3초(1초 + RTT 고려) 정도로 설정하는 것이 좋습니다. → (패킷이 2번 유실 되었을 때 파악하기까지 대략 3초가 걸림)
2. 패킷이 유실되었을 때
- 이런 상황에서는, Retransmission TimeOut(RTO) 를 고려해야 합니다. (재선송에 소요되는 시간)
- 패킷에 대한 응답이 RTO 이내에 도착하지 않으면 유실로 간주 합니다.
- RTO는 RTT를 기반으로 계산 됩니다.
1) 하지만 RTT가 아무리 짧아도 RTO 의 최소값은 있습니다. ( = 1/5초 = 200ms)
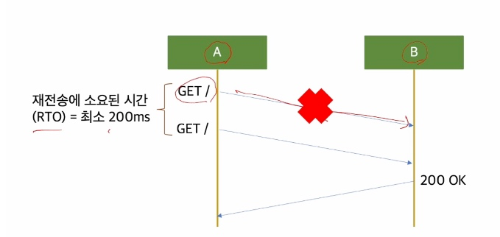
2) RTT가 10ms 라고 가정하면, 310ms 에 처리 가능한 요청이 중간에 패킷 유실로 인해(+200ms) 510ms 가 소요
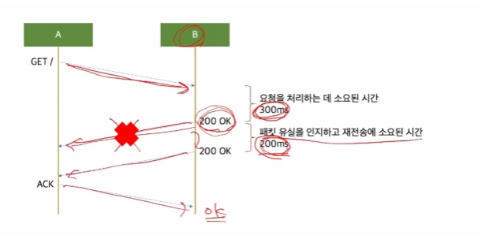
👏🏻Read Timeout 설정
- 프로세싱 시간을 고려하고 최소한 한 번의 패킷 유실을 방어 할 수 있어야 합니다.
- 그래서 1초(프로세싱 시간 + RTO 고려) 정도로 설정하는 것이 좋습니다.
✔️ 문제 원인
📌 하지만 프로세싱 시간이 전부 다름으로 → 프로세싱 시간이 Read Timeout 시간을 넘겼을 때간헐적으로 Time Out 이 빈번하게 일어날 수 있습니다.
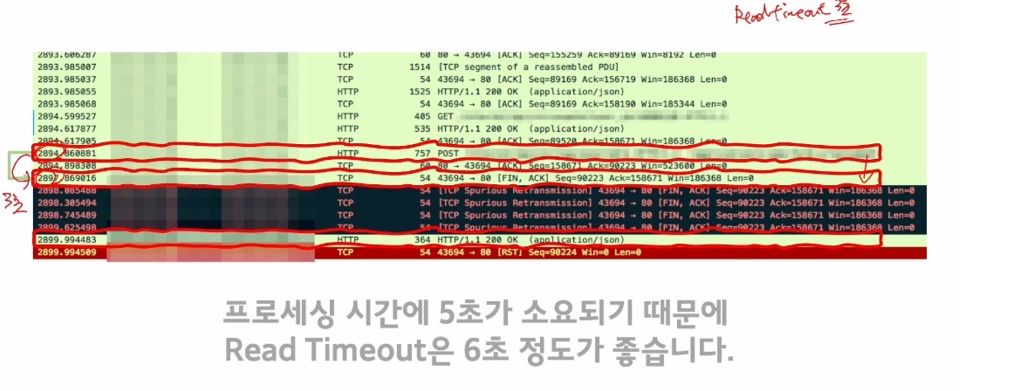
강의에서또한, ReadTimeout 은 3초인데 → 종종 프로세싱 시간이 6초가 걸리는 로직이 있어 TimeOut 이 발생했다고 합니다.
👏🏻 프로세싱 시간이 이렇게 오래걸릴때는, 프로세싱 시간을 최적하기 전까지는 Read Timeout 시간을 늘려서 서비스의 가용성을 챙기는 것도 문제를 해결하는 한가지 방법이다
3. 간헐적인 커넥션 종료 에러
HTTP Keepalive Timeout 으로 인한 장애
✔️ 장애 현상
- 간헐적으로 API 호출 시 커넥션 에러가 발생
- error code : Connection prematurely closed BEFORE response

✔️ 메트릭 수집
- netstat 을 통해 네트워크 연결은 잘 되어 있는지 확인
- tcpdump 를 통해 패킷들의 흐름을 수집 후 분석
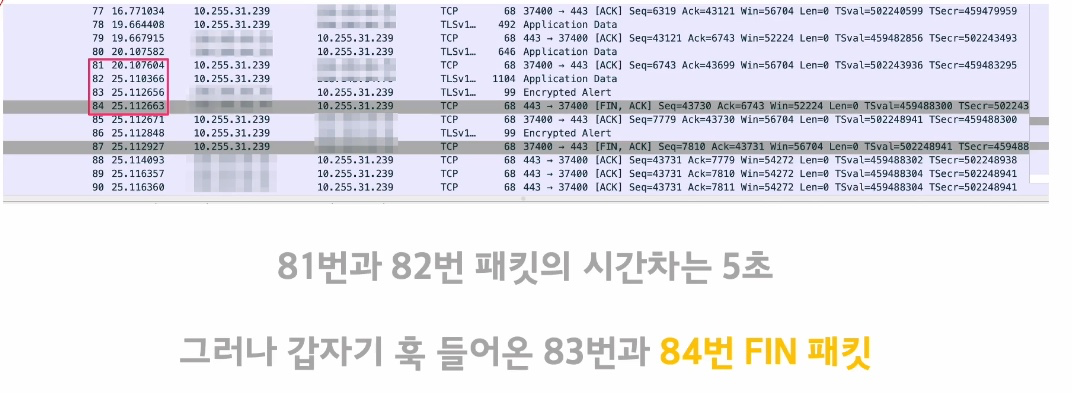
✔️ 장애 상황
- 83 번 패킷에 대한 응답으로 84번 패킷이 FIN 패킷을 보내는 것을 확인
- 상대방 서버가 갑자기 연결을 끊었다..?
✔️ HTTP KeepAlive
HTTP는 원래 Stateless 의 특징을 가지고 있습니다.
- 따라서, HTTP 통신을 하고 나면 연결을 끊는 것이 원래 스펙 입니다.
- 하지만 HTTP/ 1.1 이 되면서 자원 낭비를 줄이기 위해 Connection: Keep-Alive 헤더를 제공 합니다.

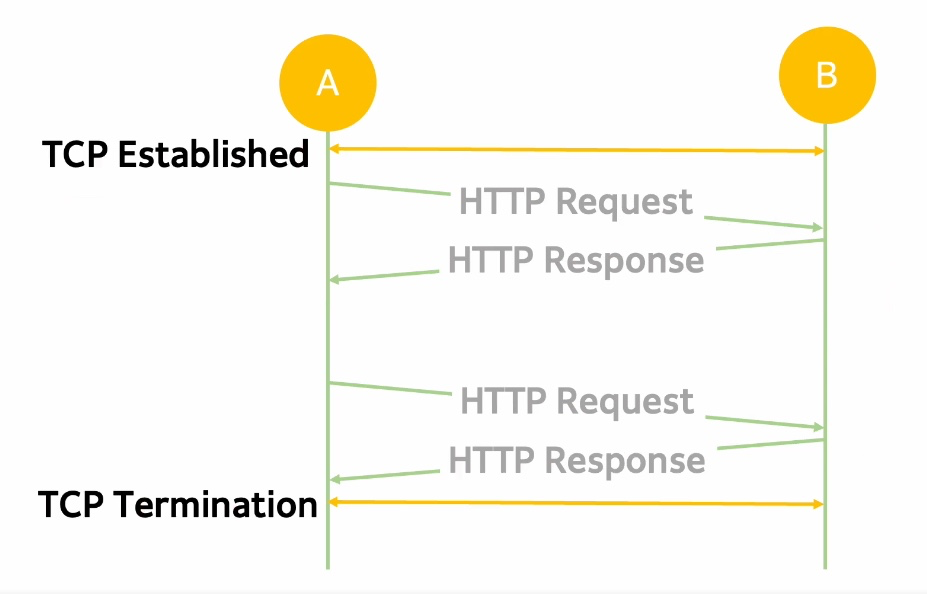
(좌) : 매번 연결 마다 통신을 주고받고, 연결을 끊었다 다시 연결을 반복
(우) : 한번 연결이 되면 계속 연결상태를 유지하다가 → HTTP KeepAlive 시간 안에 요청이 들어오지 않으면 연결을 끊음
✔️ 장애 상황 분석
- KeepAlive 타이밍이 안 맞는 상황
- 양방향 통신 중 KeepAlive 시간안에 요청이 들어오지 않아 상대방 쪽에서 연결을 끊는 상황
- 이러한 상황은, 매우 정상적인 상황이기도 함 → 하지만 간헐적으로 계속 connection error 가 나오기 때문에 대응은 필요
✔️ 장애 대응
- 요청할 때 Connection: close 헤더를 포함시켜서 HTTP KeepAlive 를 사용하지 않는다.
- 단점 : 성능이 저하 된다.
- 상대방 서버의 HTTP keepalive-timeout 을 늘려 달라고 한다.
- 단점 : 에러 발생 빈도는 줄겠지만 에러가 사라지지는 않는다.
- 상대방 서버보다 idle timeout을 짧게 가져간다.
- 호출하는 쪽의 idle Timeout 을 수정
- 상대방 서버의 keepalive-timeout보다 호출하는 쪽의 idle-Timeout을 짧게 하여 연결을 먼저 끊도록 합니다.
→ 해당 방법은 Reactor Netty의 공식문서 대응 가이드에도 명시되어 있습니다.

(예시)
- 상대방 서버의 keepalive-timeout이 5초로 예상되어 → Idle Timeout을 3초로 수정
- 상대방과 연결을 맺고 HTTP 요청을 보낸 후 3초 동안 새롭게 보낼 요청이 없다면 연결을 먼저 끊는다.
- 이렇게 되면, 호출하는 쪽이 연결을 먼저 끊기 때문에 Connection-timeout 이 발생하지 않습니다.
4. 간헐적인 타임아웃
JVM Full-GC로 인한 장애
✔️ 장애 현상
- 간헐적으로 API 호출 시 타임아웃 에러가 발생
- error code : [WARN] - from application in application-akka.actor.default-dispatcher-3 xxx is too slow [ElpasedTime: 1086ms]
✔️ 메트릭 수집
- tcpdump 낚시 → 타임아웃이 발생했던 순간의 pcap 파일 분석
✔️ 장애 상황
- 내가 주는 요청 자체에서 문제가 발생했다.
- 응답 늦게 받은 것 x, 못 받은 것 도 x 아님 → 패킷 생성 자체가 늦어졌다?

✔️ 장애 대응
2가지 상황을 생각해볼 수 있습니다.
- 서버에 부하가 극심해서 패킷 생성 자체가 늦어졌다.
- 체크포인트 [Load Average 및 CPU 사용량 체크] → 높지 않았다면 아래 이유일 수 있습니다.
- 애플리케이션의 프로세싱 시간이 길어져서 패킷 생성이 늦어졌다.
- 수집한 데이터를 바탕으로 개발팀과 논의 → 네트워크나 인프라적인 문제가 보이지 않았기 때문에
- 애플리케이션에 영향을 줄 만한 로직이 있는지?
- 결론적으로 → JVM Full-GC 로 인한 멈춤 현상이였다고 합니다.
✔️ Full GC 란
- GC 쓰레드를 제외한 다른 쓰레드들이 멈추는 현상
- → 요청 순간에 java 에서 사용하는 일부 라이브러리가 Full-GC를 일으키고 이로인해 → 요청을 제때 하지 못한 상황 → 에러
5. EC2 CPU 이상 동작 사례
물리서버의 CPU 불량으로 인한 장애
✔️ 장애 현상
- 간헐적으로 CPU Usage 높다는 알람 발생
- 👏🏻 여기서 포인트 → 모든 서버에서 발생하지는 않고 "일부 서버" 에서만 발생했다

✔️ 메트릭 수집
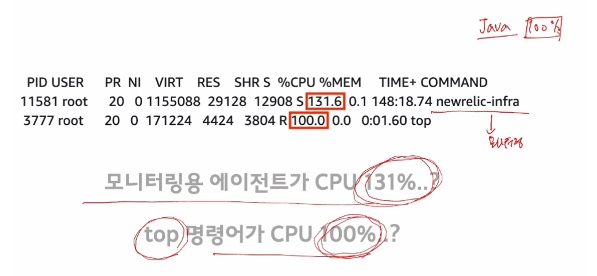
- top 을 통해 어떤 프로세스가 CPU를 사용하는지 확인하였더니 → JAVA 프로세스가 100% 사용하고 있었음
1번째 조치
- 구글링을 통해 JAVA, 특히 tomcat 이 CPU를 점유하는 현상이 검색되었다고 합니다,
- /dev/random 블로킹 이슈 (난수 생성을 위한 코드가 있을경우, /dev/random 을 읽어들일때 CPU 점유율이 올라감) 조치했지만 → 해결되지 않았다.
→ 잘못된 점
- 저게 원인이였다면 모든 서버에서 CPU 이슈가 발생했어야 합니다. (똑같은 tomcat, os 이기 때문)
- 결과적으로, 전역적인 원인이 아니였음
2번째 조치
- 이슈가 발생하는 서버만 서비스에서 제외
- ASG (Auto-Scaleling Group) 에서 제외시키고, 삭제 방지 기능 활성화(ASG 에서 EC2를 제외할 시 ASG가 인스턴스를 종료 후 재실행 시키기 때문에 에러파악이 힘들어짐) 후 분석 시작
- 그런데 다시 top 으로 확인하니 이상한 것들도 CPU 사용률을 많이 먹고있었다고 합니다.
- 즉, 서버 자체가 이상함을 알 수 있습니다.
↓
👏🏻 /proc/cpuinfo 를 확인하였더니 (CPU 자체에 대한 의구점) → MHz 가 너무 작게 나온다.

✔️ CPU MHz가 변경되는 상황
CPU의 C-state 와 P-State 이 두 기능에 의해 MHz가 유동적일 수 있습니다.
C-State
- 전력 소모량을 줄이기 위해서 일부 CPU 코어를 비활성화 하는 기능
- 총 4개인 코어를 평상시에 코어를 1,2 개만 사용한다면 안쓰는 코어를 disable 시킴
- 다시 써야하면 하나씩 깨움 → 약간의 성능저하 발생
P-State
- 작업 부하에 따라서 CPU 의 전압과 MHz를 조절하는 기능
- 서버의 처리량에 따라 MHz를 유동적으로 변경하는 기능
✔️ 다시 문제해결 과정
aws 문서에서는 → turbostat 명령을 이용해 강제로 CPU MHz를 끌어오릴 수 있는 방법이 소개되어있습니다.
📌 하지만 따라해봤자 MHz 회복되지않았고 → 결과적으로는 하드웨어의 문제였다고 합니다. (aws 팀과 문의했다고 함)

이걸로 강의 정리 끝!
'운영체제 > Linux' 카테고리의 다른 글
| [Linux] tcpdump - 네트워크 트러블 슈팅 도구 (리눅스 패킷 수집 및 분석하기) (0) | 2023.09.02 |
|---|---|
| [Linux] netstat - 리눅스 네트워크 연결 정보 (0) | 2023.09.01 |
| [Linux] top - 리눅스 CPU 사용량 보기 (0) | 2023.08.31 |
| [Linux] df - 디스크 사용량 모니터링 하기 (0) | 2023.08.28 |
| [Linux] free - 메모리 사용량 확인하기 (0) | 2023.08.24 |