이번 글에서는, JPA N+1 문제가 무엇인지,, 왜일어나고,,, 어떤 해결방법이 있는지 알아보고
내 프로젝트에 적용해 보고자 한다!
결과적으로, N+1 문제를 해결하면서 페이지네이션까지 하고자한다!
JPA N+1 문제
JPA N+1문제란, JPA가 데이터를 조회할 때, 연관관계 매핑에있는 객체들을 함께 조회하여(N개 만큼) 추가 쿼리가 발생하는 문제를 N+1 문제라고 합니다.
- JPA는 JPQL을 생성하여 실행하게 되는데, 엔티티 객체와 필드이름을 이용하여 쿼리를 만든다.
- 이때 객체의 연관관계 매핑에 의해서 관계가 맺어진 다른 객체들이 함께 조회된다.

지연로딩시 N+1 문제가 발생하지 않나요?
JPA의 FetchType으로는 즉시로딩과 지연로딩 이 있습니다. (이전 글 참고)
즉시로딩시, 연관된 모든 객체를 조회하기 때문에 N개의 추가쿼리가 발생하게 됩니다.
하지만, 지연로딩 시에는, 필요할 때에만 연관된 객체를 가져오기때문에 실제 쿼리에서는 추가 쿼리가 발생하진 않습니다.

그럼 이제 N+1문제를 해결한 걸까요?
아닙니다,, FetchType을 Lazy로 설정한다는 것은 연관관계 데이터를 프록시 객체(가짜 객체) 로 바인딩한다는 것이라고 합니다.
결국, 이 프록시객체만으로 사용하지 않는 이상, FetchType을 변경하는 것은 N+1 문제 발생시점을, 데이터를 로드 시점에 일으킬지, 아니면 데이터를 사용 시점에 일으킬지 미루는 것 정도의 차이만 있다고 합니다.
(예시)
Lazy타입으로 불러온 findAll() 객체를, 하나씩 조회하는 반복문 로직
List<Owner> everyOwners = ownerRepository.findAll();
List<String> catNames = everyOwners.stream().flatMap(it -> it.getCats().stream().map(cat -> cat.getName())).collect(Collectors.toList());
assertFalse(catNames.isEmpty());
객체 전부를 불러왔지만, 연관된 매핑관계에있는 객체의 정보는 불러오지 않기 때문에, 해당 객체의 정보로 조건문을 사용하여 쿼리문을 별도로 생성하여 값을 불러와 데이터의 개수만큼의 N개의 쿼리문이 추가로 발생되어집니다.

N+1 해결방법
n+1문제는, 연관 매핑된 객체 테이블 전체를 가져오는게 아닌, 그 컬럼 하나씩을 조회하는 쿼리 N개가 생성되는 아주아주 비효율적인 문제인데,,
n+1 해결방법으로 제가 찾아본 방법은 크게 2가지 있습니다.
- 패치 조인(Fetch join)
- 엔티티 그래프(EntityGraph)
1) Fetch join (패치 조인 or 조인 패치)
패치 조인이란,
- fetch join이란, JPQL에서 성능 최적화를 위해 제공하는 기술입니다.
- fetch join은 일반 조인과는 다릅니다. SQL 조인 종류가 아닌, JPQL에서 최적화를 위해 제공하는 기술입니다.
- fetxh join을 사용하면, JPQL은, 연관된 객체의 모든 정보 하나의 객체로 한번에 불러옵니다.
- 일반 조인과는 달리, 엔티티의 특정 속성만을 가져올 수 없습니다.
fetch join의 단점
- 패치 조인 대상에는 별칭을 줄 수 없다. (where m.~ 이런 것 쓰면 안 됨)
- 둘 이상의 컬렉션은 패치 조인 할 수 없다.
- 컬렉션을 패치 조인하면 페이징 API를 사용할 수 없다.
조인은 Repository 단에서 @Query 애너테이션을 이용해 JPQL로 쿼리를 작성해야 합니다.
fetch join은 join 뒤에 fetch 라는 키워드 사용만으로 간단히 해결됩니다.
일반 조인 사용법
// TeamRepository.java
@Query("SELECT distinct t FROM Team t join t.members")
public List<Team> findAllWithMemberUsingJoin();- 실제로 일반 join은 실제 쿼리에 join을 걸어주기는 하지만 join대상에 대한 영속성까지는 관여하지 않습니다.
- 오직 join만 걸고 실제 영속성 컨텍스트에는 SELECT 대상만을 담게 됩니다.
- 따라서 Select 해오지 않은, 컬럼에 접근시 NullPoint 에러가 발생됩니다.

패치 조인 사용법
- join과 사용법 자체는 동일합니다. 단지 fetch join 명령어로 join을 할 뿐입니다.
- 패치 조인은 실제 질의하는 대상 Entity와 Fetch join이 걸려있는 Entity를 포함한 컬럼 함께 SELECT합니다.
1) 요런 형식으로 Repository에 쿼리문 정의
@Repository
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("select m from Member m join fetch m.team ") // (1)
List<Member> findAllMembers();
}
2) fetch join 결과 확인
// TeamRepository.java
@Query("SELECT distinct t FROM Team t join fetch t.members")
public List<Team> findAllWithMemberUsingFetchJoin();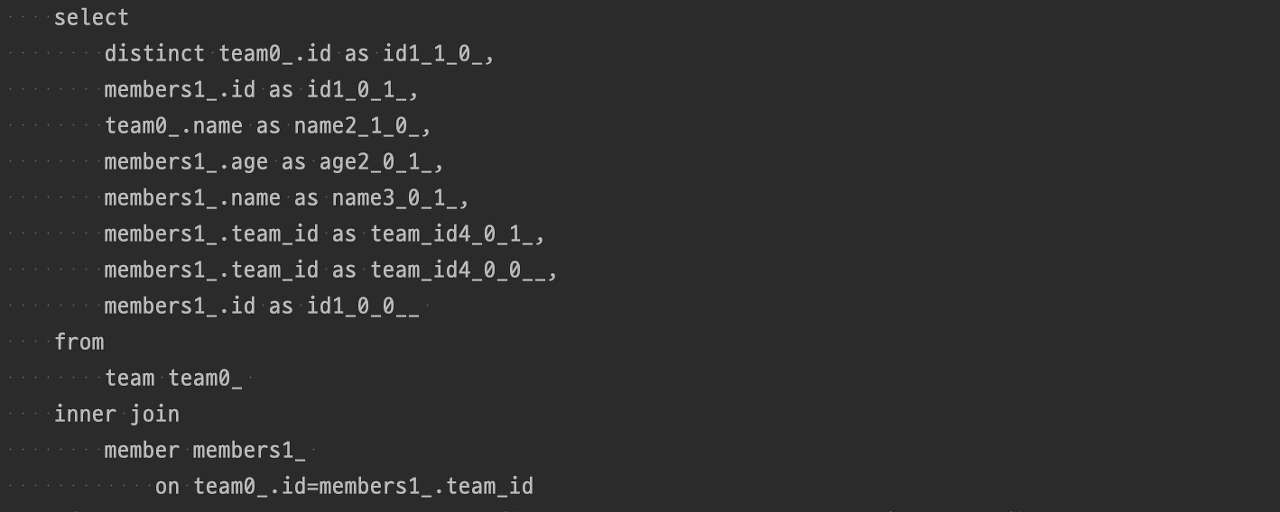
2) EntityGraph (엔티티 그래프)
- fetch join을 위해 매 번 JPQL을 작성하는 건 너무나 귀찮고, 수정해야할 사항이 많아보입니다.
- 또한 JpaRepository가 기본으로 제공하는 기능을 사용할 수 없다면 갓프링이라고 부를 수 없겠죠.
스프링 데이터 JPA에서는 이 문제를 @EntityGraph를 통해 해결합니다.
기본으로 제공되는 메서드 중 findAll()에 해당 기능을 적용하고 싶다면 아래처럼 Repository를 수정해줍니다.
@Repository
public interface MemberRepository extends JpaRepository<Member, Long> {
@Override // (1)
@EntityGraph(attributePaths = {"team"}) // (2)
List<Member> findAll();
}(1) JpaRepository.findAll()을 override 합니다.
(2) @EntityGraph 애너테이션을 추가하고 attributePaths에 Member 객체와 Join할 객체를 표기합니다.

select 쿼리가 한 번만 수행된 것을 확인할 수 있습니다.
추가로 @Query를 이용해 JPQL을 작성(join query 없이)한 곳에 @EntityGraph를 사용하셔도 동일하게 동작합니다.
@Query("select m from Member m")
@EntityGraph(attributePaths = {"team"})
List<Member> findAllMembers(); // JPQL을 이용해도 가능
@EntityGraph(attributePaths = {"team"})
Member findByUsername(String username); // 메서드 쿼리를 이용해도 가능
문제 상황 (N+1 직접 해결하기)
인제 프로젝트 성능개선을 위해,,, 이번엔 N+1 문제를 해결해 보고자 한다.
처음 JPA쿼리문을 확인해보았을때, 이유를 알 수없는 수많은 쿼리가 생성되는 것을 확인했었다...
당시에는 뭐가 문제인지 모른체 시간상 이상하다하고 넘겼지만,,, 이젠 넘어갈 수없어
이걸 자세히 보니, 모든 프로필을 조회하는 1개의 쿼리와, 연관된 모든 유저를 조회하는 n의 쿼리문이 생성되는 것을 볼 수 있었다.


1) ManyToOne N+1 해결해보기
(1) Fetch Type LAZY 확인
Profile 도메인
@Getter
@Setter
@Entity // 테이블과 연계됨을 스프링에게 알려줍니다.
public class Profile extends Timestamped { // 생성,수정 시간을 자동으로 만들어줍니다.
@GeneratedValue(strategy = GenerationType.AUTO)
@Id
private Long idx;
//생략
@JsonIgnore
@ManyToOne(fetch=FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;먼저 홈화면은, 추가로 연관된 객체를 이용하지 않기때문에, LAZY 타입으로 시험을 해보았습니다.
@JsonIgnore
@ManyToOne(fetch=FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;- 도중에 com.fasterxml.jackson.databind.exc.InvalidDefinitionException에러가 난다면 -> https://thalals.tistory.com/291
결과는 Profile 객체만 불러옴!
하지만, N+1 문제가 해결된것은아니다, 연관 객체를 불러올때 n+1 문제가 추가로 발생한다.

- Repostiroy 단에서 fetch join을 사용해보았다.
- 연관된 user 정보까지 join해온다.
- manytoone은 아주 간단해서 기분이 좋다
public interface ProfileRepository extends JpaRepository<Profile, Long> {
@Override
@Query("SELECT p FROM Profile p join fetch p.user")
List<Profile> findAll();
List<Profile> findByUserId(Long userId);
} //Jpa 테이블 상속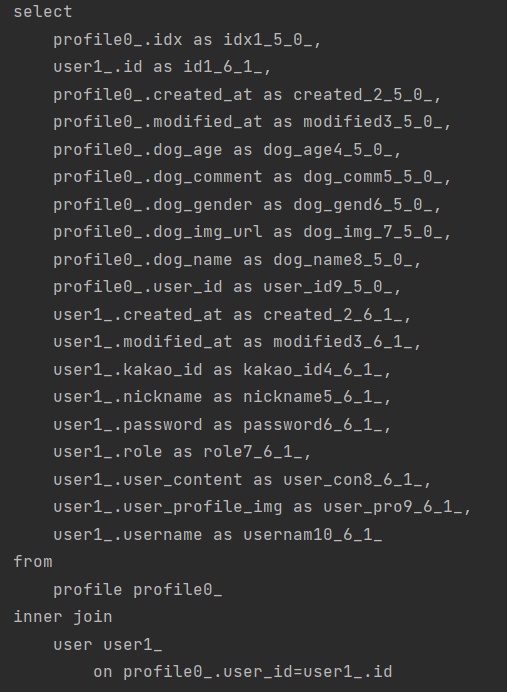
2) OneToMany N+1 해결하기
이제 본격적으로 해보자
Post 도메인
- User 엔티티와는 ManyToOne
- comments 와 likes 와는 OneToMany 관계를 맺고있다.
@Entity
@Getter
@Setter
@NoArgsConstructor
@DynamicInsert
@Table(name = "post")
public class Post extends Timestamped {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "id")
private Long idx;
//컬럼 생략
@JsonIgnore
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "user_id")
private User user;
//좋아요 수 count 컬럼 - 가상
// @Column(columnDefinition = "int default 0")
@Formula("(select count(*) from post_like l where l.post_id = id)")
private int countOfLikes;
@JsonIgnore
@BatchSize(size = 100)
@OneToMany(mappedBy = "post", cascade=CascadeType.ALL, fetch = FetchType.LAZY)
private List<PostComment> comments = new ArrayList<PostComment>();
@JsonIgnore
@BatchSize(size = 100)
@OneToMany(mappedBy = "post", cascade=CascadeType.ALL, fetch = FetchType.LAZY)
private List<PostLike> likes = new ArrayList<PostLike>();
}
1. Fetch join으로 전부 끌어오기
- 우선 fetch join으로 전부 끌어와 보았다.
- 역시나 에러가 난다..ㅠ
- 알아보니, ~ToMany는 fetch join과 함께 사용하기 힘든 것 같다.(2개 이상의 fetch join을 하면 안됨)
- join 시, 1대N개의 관계를 맺는 경우 카디널 곱이 일어나, 컬럼이 무수히 많아질 수 있기 때문이다.
- ~ToOne은 무조건 하나의 컬럼에 매핑되기 때문에, 추가 컬럼이 생성되지않아 얼마든지 fetch join 해도 된다.
@Query(value = "SELECT p FROM Post p JOIN FETCH p.user u JOIN FETCH p.likes JOIN FETCH p.comments")
Page<Post> findWithPagination(Pageable pageable);JPA에서 Fetch Join의 조건은 다음과 같다.
- ToOne은 몇개든 사용 가능
- ToMany는 1개만 가능
2. join 문으로 끌어오기
- 그다음으로 해본 방법은 일반 join 문이였다.
- fetch join과 일반 join은 JPA에서 확연히 다르게 동작한다.
- 결과적으로는 join으로 oneToMany를 해결할 수 없었다.
- fetch join은 불러온 데이터를 영속성 컨텍스트에 저장하지만, join은 영속성 컨텍스트에 저장하지 않습니다.
- 실 데이터가 들어가지 않기 때문에, 그저 검색 조건으로만 사용할 때는 join이 더 좋아보이긴 하는군요,,
너무 많은 시도를 해서,, 기록이 없어요ㅠㅠ
→ N+1문제를 해결하는 다른 방법?
- 직접 해본 것은 아니고, 순환참조 문제를 해결해보면서 생각해 본 방법이 있습니다.
- Repository에서, join으로 데이터를 불러오고 불러온 데이터를 바로 DTO 객체에 담아서 리턴해 준다면, 연관된 객체까지 DTO에 저장이 될거라고 생각해 N+1 문제가 발생하지 않을 것 같습니다.
3. BatchSize + Join Fetch (정답)
- 후,, 이것이 복수의 oneToMany n+1 문제를 해결할 수 있는 거의 유일한 방법인것 같다.. (다른 방법이 있다면 제발 알려주세요 ㅠㅠㅠㅠㅠ)
- 먼저 ~ToOne은 전부 fetch join으로 데이터를 끌어와 영속성 컨텍스트화 시킨다. (N+1 문제가 일어나지 않도록)
- 전역적으로 batch_size를 지정하거나 @BatchSize 어노테이션으로 batch size를 지정한다.
- 이렇게 한다면 N+1 문제를 -> 1+1+1...~~ (연관된 엔티티의 컬럼 개수가 아닌 그냥 연관 개수로!!) 해결가능하다!!
- 나와 같은경우, 쿼리가 22개에서 4개로 줄었다..!
BatchSize란
- batchSize란, 쉽게 말해, N+1 문제가 터지기 전에, 데이터를 미리미리 가져올 사이즈를 정한다는 것이다.
- n+1은, 데이터를 조회할 때, 그 컬럼을 1개씩 조회하는 쿼리가 생성되 N의 쿼리가 발생하는 문제이다.
- batch size를 100으로 지정하면, 이걸 in 쿼리로 100개씩 불러오겠다는 의미이다.
BatchSize + Join Fetch 사용법
(1) 전역적으로 batch size 설정
- application.yml에 그 크기를 전역적으로 설정하는 방법이다.
- 이렇게 하면 모든 데이터에 batch size가 설정된다.
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 100
(2) 엔티티 필드에 batchsize 하나씩 설정
- domain 컬럼 필드에 그 크기를 일일히 설정하는 방법이다.
- @BatchSize 어노테이션을 이용한다.
- ~ToOne 엔티티는 필드가 아닌 해당 엔티티 최 상단에 어노테이션을 추가해준다 (Class 바로위)
@JsonIgnore
@BatchSize(size = 100)
@OneToMany(mappedBy = "post", cascade=CascadeType.ALL, fetch = FetchType.LAZY)
private List<PostComment> comments = new ArrayList<PostComment>();
@JsonIgnore
@BatchSize(size = 100)
@OneToMany(mappedBy = "post", cascade=CascadeType.ALL, fetch = FetchType.LAZY)
private List<PostLike> likes = new ArrayList<PostLike>();
BatchSize의 적정크기
- 그럼 무조건 배치 사이즈를 크게 할수록 유리할까?
- 아니다, batch size는 어플리케이션과 db에 순간적으로 들어가서, 얼마나 부하를 견딜 수 있는 지가 중요하다.
- 보통 100~1000을 추천한다고 김영한 갓님이 그러셨다,,ㅎㅎ
Fetch join과 페이지네이션
Repository
@Query(value = "select p from Post p join fetch p.user u", countQuery = "select count(p) from Post p")
Page<Post> findWithPagination(Pageable pageable);
- fetch join을 사용하면 페이지네이션 API를 사용하지 못한다고 구글링에서 많이들 말한다.
- 하지만 이렇게 하니, 사용이 가능했다.
- 아마 ~ToOne은 컬럼이 증가되지 않기 때문에 가능한 것 같다.
- 단, count 쿼리를 직접 지정해 주어야한다, fetch join 사용시 어떤 컬럼이 메인 컬럼이고 이 컬럼으로 카운팅을 하라고 말해주어야한다.
결과
select
post0_.id as id1_2_0_,
user1_.id as id1_6_1_,
post0_.created_at as created_2_2_0_,
post0_.modified_at as modified3_2_0_,
post0_.content as content4_2_0_,
post0_.img as img5_2_0_,
post0_.title as title6_2_0_,
post0_.user_id as user_id8_2_0_,
post0_.view as view7_2_0_,
(select
count(*)
from
post_like l
where
l.post_id = post0_.id) as formula1_0_,
user1_.created_at as created_2_6_1_,
user1_.modified_at as modified3_6_1_,
user1_.kakao_id as kakao_id4_6_1_,
user1_.nickname as nickname5_6_1_,
user1_.password as password6_6_1_,
user1_.role as role7_6_1_,
user1_.user_content as user_con8_6_1_,
user1_.user_profile_img as user_pro9_6_1_,
user1_.username as usernam10_6_1_
from
post post0_
inner join
user user1_
on post0_.user_id=user1_.id
order by
post0_.created_at desc limit ?
이런식의 쿼리 문이 생성된다~~
select
comments0_.post_id as post_id5_3_2_,
comments0_.idx as idx1_3_2_,
comments0_.idx as idx1_3_1_,
comments0_.created_at as created_2_3_1_,
comments0_.modified_at as modified3_3_1_,
comments0_.comment as comment4_3_1_,
comments0_.post_id as post_id5_3_1_,
comments0_.user_id as user_id6_3_1_,
user1_.id as id1_6_0_,
user1_.created_at as created_2_6_0_,
user1_.modified_at as modified3_6_0_,
user1_.kakao_id as kakao_id4_6_0_,
user1_.nickname as nickname5_6_0_,
user1_.password as password6_6_0_,
user1_.role as role7_6_0_,
user1_.user_content as user_con8_6_0_,
user1_.user_profile_img as user_pro9_6_0_,
user1_.username as usernam10_6_0_
from
post_comment comments0_
left outer join
user user1_
on comments0_.user_id=user1_.id
where
comments0_.post_id in (
?, ?, ?, ?, ?
)
그럼 모두 화이팅,,,,,ㅠ

흨흨흨,,, 너무 힘들었어ㅡㅡㅡㅠㅠㅠㅠㅠ
*참고
- N+1 문제 : https://incheol-jung.gitbook.io/docs/q-and-a/spring/n+1
- N+1 해결방법 : https://jojoldu.tistory.com/165
- fetch join 한계 : https://velog.io/@cherish8513/JPQL-%ED%8C%A8%EC%B9%98-%EC%A1%B0%EC%9D%B8
- 일반조인 vs 패치조인 : https://gilssang97.tistory.com/45
- 조인 사용법 : https://cobbybb.tistory.com/18
- 김영한 JPA 활용 2편
'Spring > Spring Boot' 카테고리의 다른 글
| [Spring] 스프링 부트 JPA 페이징 성능 개선 - querydsl 페이지네이션(오프셋 페이징, 커서 페이징, querydsl 정렬) (0) | 2022.04.10 |
|---|---|
| [Spring/스프링] springboot gradle - XSS 스크립트 오류 해결하기 (with @RequestBody) (4) | 2022.04.05 |
| [Spring] JPA 즉시 로딩과 지연 로딩 (0) | 2022.03.23 |
| getter setter를 사용하는 이유 (0) | 2022.02.24 |
| [Spring] AOP란 - (AOP, Spring AOP, AOP 어노테이션) (0) | 2022.01.18 |